Презентация Параллельное программирование с использованием OpenMP. Лекция 1 онлайн
На нашем сайте вы можете скачать и просмотреть онлайн доклад-презентацию на тему Параллельное программирование с использованием OpenMP. Лекция 1 абсолютно бесплатно. Урок-презентация на эту тему содержит всего 44 слайда. Все материалы созданы в программе PowerPoint и имеют формат ppt или же pptx. Материалы и темы для презентаций взяты из открытых источников и загружены их авторами, за качество и достоверность информации в них администрация сайта не отвечает, все права принадлежат их создателям. Если вы нашли то, что искали, отблагодарите авторов - поделитесь ссылкой в социальных сетях, а наш сайт добавьте в закладки.
Оцените презентацию от 1 до 5 баллов!
- Тип файла:ppt / pptx (powerpoint)
- Всего слайдов:44 слайда
- Для класса:1,2,3,4,5,6,7,8,9,10,11
- Размер файла:1.31 MB
- Просмотров:159
- Скачиваний:0
- Автор:неизвестен
Слайды и текст к этой презентации:
№1 слайд

Содержание слайда:
№2 слайд

Содержание слайда: Параллельное программирование
с использованием OpenMP
№3 слайд

Содержание слайда: ОСНОВЫ ПОДХОДА
№4 слайд
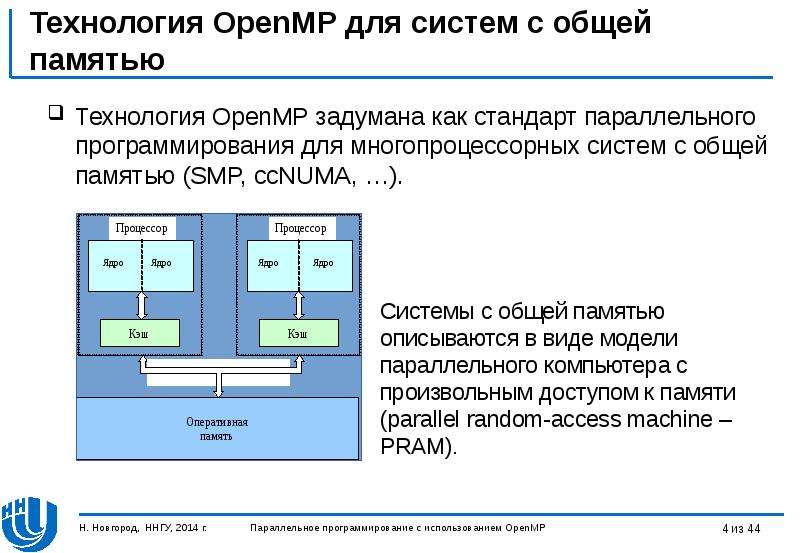
Содержание слайда: Технология OpenMP для систем с общей памятью
Технология OpenMP задумана как стандарт параллельного программирования для многопроцессорных систем с общей памятью (SMP, ccNUMA, …).
Системы с общей памятью описываются в виде модели параллельного компьютера с произвольным доступом к памяти (parallel random-access machine – PRAM).
№5 слайд

Содержание слайда: Способы разработки программ для параллельных вычислений…
Способ 1: автоматическое распараллеливание последовательных программ.
возможности автоматического построения параллельных программ ограничены.
Способ 2: расширение существующих алгоритмических языков средствами параллельного программирования.
Способ 3: использование новых алгоритмических языков параллельного программирования.
Примечание: Способы 2-3 приводят к необходимости значительной переработки существующего программного обеспечения.
.
№6 слайд

Содержание слайда: Способы разработки программ для параллельных вычислений…
Способ 4: использование тех или иных внеязыковых средств языка программирования.
Примеры средств – директивы или комментарии, которые обрабатываются специальным препроцессором до начала компиляции программы.
Директивы дают указания на возможные способы распараллеливания программы, при этом исходный текст программы остается неизменным.
Препроцессор заменяет директивы параллелизма на дополнительный программный код (как правило, в виде обращений к процедурам параллельной библиотеки).
При отсутствии препроцессора компилятор построит исходный последовательный программный код.
№7 слайд

Содержание слайда: Способы разработки программ для параллельных вычислений
Способ 4: Положительные стороны:
Снижает потребность переработки существующего программного кода.
Обеспечивает единство программного кода для последовательных и параллельных вычислений, что снижает сложность развития и сопровождения программ.
Позволяет осуществлять поэтапную (инкрементную) разработку параллельных программ.
Именно этот подход и является основой технологии OpenMP
№8 слайд
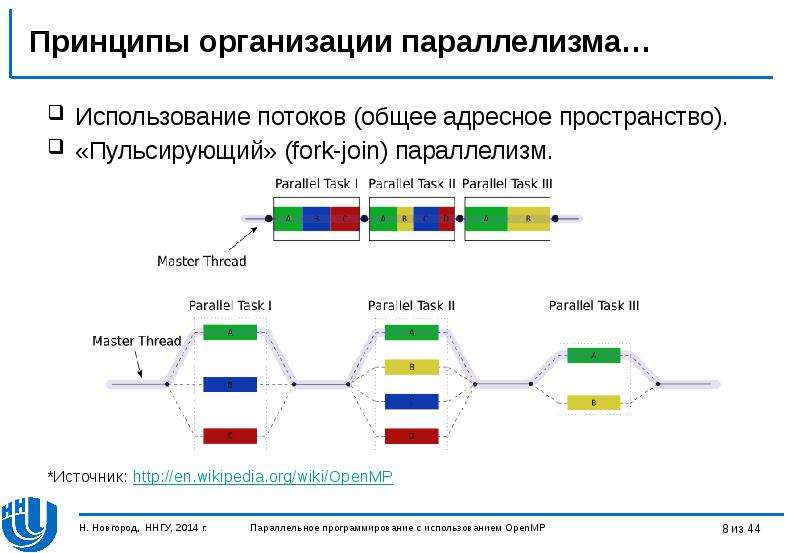
Содержание слайда: Принципы организации параллелизма…
Использование потоков (общее адресное пространство).
«Пульсирующий» (fork-join) параллелизм.
*Источник: http://en.wikipedia.org/wiki/OpenMP
№9 слайд

Содержание слайда: Принципы организации параллелизма
При выполнении обычного кода (вне параллельных областей) программа исполняется одним потоком
(master thread).
При появлении директивы parallel происходит создание “команды” (team) потоков для параллельного выполнения вычислений.
После выхода из области действия директивы parallel происходит синхронизация, все потоки, кроме master, уничтожаются (или приостанавливаются).
Продолжается последовательное выполнение кода (до очередного появления директивы parallel).
№10 слайд

Содержание слайда: Структура OpenMP
Компоненты:
Набор директив компилятора.
Библиотека функций.
Набор переменных окружения.
Изложение материала будет проводиться на примере языка C/C++.
№11 слайд

Содержание слайда: Директивы openmp
Формат, области видимости, типы.
Директива определения параллельной области.
№12 слайд

Содержание слайда: Формат записи директив…
Формат:
#pragma omp имя_директивы [параметр,…]
Пример:
#pragma omp parallel default(shared) private(beta,pi)
Примечание: На английском языке для термина «параметр» используется обозначение «clause».
№13 слайд
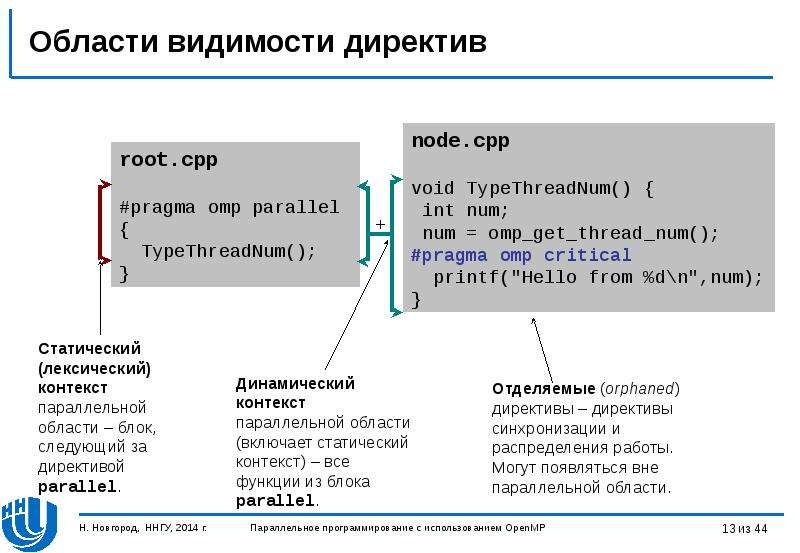
Содержание слайда: Области видимости директив
№14 слайд

Содержание слайда: Типы директив
Определение параллельной области.
Разделение работы.
Синхронизация.
№15 слайд

Содержание слайда: Определение параллельной области
Директива parallel (основная директива OpenMP):
Когда основной поток выполнения достигает директиву parallel , создается набор (team) потоков.
Входной поток является основным потоком (master thread) этого набора и имеет номер 0.
Код области дублируется или разделяется между потоками для параллельного выполнения.
В конце области обеспечивается синхронизация потоков – выполняется ожидание завершения вычислений всех потоков.
Далее все потоки завершаются, и последующие вычисления продолжает выполнять только основной поток.
№16 слайд

Содержание слайда: Формат директивы
Формат директивы parallel :
#pragma omp parallel [clause ...]
structured_block
Возможные параметры (clauses):
if (scalar_expression)
private (list)
firstprivate (list)
default (shared | none)
shared (list)
copyin (list)
reduction (operator: list)
num_threads(integer-expression)
№17 слайд

Содержание слайда: Пример использования директивы…
#include <omp.h>
void main() {
int nthreads, tid;
// Создание параллельной области
#pragma omp parallel private(tid)
{
// печать номера потока
tid = omp_get_thread_num();
printf("Hello World from thread = %d\n", tid);
// Печать количества потоков – только master
if (tid == 0) {
nthreads = omp_get_num_threads();
printf("Number of threads = %d\n", nthreads);
}
} // Завершение параллельной области
}
№18 слайд

Содержание слайда: Пример использования директивы
Hello World from thread = 1
Hello World from thread = 3
Hello World from thread = 0
Hello World from thread = 2
№19 слайд

Содержание слайда: Установка количества потоков
Способы задания (по убыванию старшинства)
Параметр директивы:
num_threads(N)
Функция установки числа потоков: omp_set_num_threads(N)
Переменная окружения:
OMP_NUM_THREADS
Число, равное количеству процессоров, которое “видит” операционная система.
№20 слайд

Содержание слайда: Определение времени выполнения параллельной программы
double t1, t2, dt;
t1 = omp_get_wtime ();
…
t2 = omp_get_wtime ();
dt = t2 – t1;
№21 слайд

Содержание слайда: Директивы openmp
№22 слайд

Содержание слайда: Директивы управления областью видимости
Управление областью видимости обеспечивается при помощи параметров (clauses) директив:
shared, default
private
firstprivate
lastprivate
reduction, copyin.
Параметры директив определяют, какие соотношения существуют между переменными последовательных и параллельных фрагментов выполняемой программы.
№23 слайд

Содержание слайда: Параметр shared
Параметр shared определяет список переменных, которые будут общими для всех потоков параллельной области.
#pragma omp parallel shared(list)
Примечание: правильность использования таких переменных должна обеспечиваться программистом.
№24 слайд

Содержание слайда: Параметр private
Параметр private определяет список переменных, которые будут локальными для каждого потока.
#pragma omp parallel private(list)
Переменные создаются в момент формирования потоков параллельной области.
Начальное значение переменных является неопределенным.
№25 слайд

Содержание слайда: Пример использования директивы private
#include <omp.h>
void main () {
int nthreads, tid;
// Создание параллельной области
#pragma omp parallel private(tid)
{
// печать номера потока
tid = omp_get_thread_num();
printf("Hello World from thread = %d\n", tid);
// Печать количества потоков – только master
if (tid == 0) {
nthreads = omp_get_num_threads();
printf("Number of threads = %d\n", nthreads);
}
} // Завершение параллельной области
}
№26 слайд

Содержание слайда: Параметр firstprivate
Параметр firstprivate позволяет создать локальные переменные потоков, которые перед использованием инициализируются значениями исходных переменных.
#pragma omp parallel firstprivate(list)
№27 слайд

Содержание слайда: Параметр lastprivate
Параметр lastprivate позволяет создать локальные переменные потоков, значения которых запоминаются в исходных переменных после завершения параллельной области (используются значения потока, выполнившего последнюю итерацию цикла или последнюю секцию).
#pragma omp parallel lastprivate(list)
№28 слайд

Содержание слайда: Директивы openmp
№29 слайд

Содержание слайда: Директивы распределения вычислений между потоками
Существует 3 директивы для распределения вычислений в параллельной области:
for – распараллеливание циклов.
sections – распараллеливание раздельных фрагментов кода (функциональное распараллеливание).
single – директива для указания последовательного выполнения кода.
Начало выполнения директив по умолчанию не синхронизируется.
Завершение директив по умолчанию является синхронным.
№30 слайд

Содержание слайда: Директива for
Формат директивы for:
#pragma omp for [clause ...]
for loop
Возможные параметры (clause):
private(list)
firstprivate(list)
lastprivate(list)
schedule(kind[, chunk_size])
reduction(operator: list)
ordered
nowait
№31 слайд

Содержание слайда: Пример использования директивы for
#include <omp.h>
#define CHUNK 100
#define NMAX 1000
void main() {
int i, n, chunk;
float a[NMAX], b[NMAX], c[NMAX];
for (i=0; i < NMAX; i++)
a[i] = b[i] = i * 1.0;
n = NMAX; chunk = CHUNK;
#pragma omp parallel shared(a,b,c,n,chunk) private(i)
{
#pragma omp for
for (i=0; i < n; i++)
c[i] = a[i] + b[i];
} // end of parallel section
}
№32 слайд
Содержание слайда: Директива for. Параметр schedule
static – итерации делятся на блоки по chunk итераций и статически разделяются между потоками.
Если параметр chunk не определен, итерации делятся между потоками равномерно и непрерывно.
dynamic – распределение итерационных блоков осуществляется динамически (по умолчанию chunk=1).
guided – размер итерационного блока уменьшается экспоненциально при каждом распределении.
chunk определяет минимальный размер блока (по умолчанию chunk=1).
runtime – правило распределения определяется переменной OMP_SCHEDULE (при использовании runtime параметр chunk задаваться не должен).
№33 слайд

Содержание слайда: Пример использования директивы for
#include <omp.h>
#define CHUNK 100
#define NMAX 1000
void main() {
int i, n, chunk;
float a[NMAX], b[NMAX], c[NMAX];
for (i=0; i < NMAX; i++)
a[i] = b[i] = i * 1.0;
n = NMAX; chunk = CHUNK;
#pragma omp parallel shared(a,b,c,n,chunk) private(i)
{
#pragma omp for schedule(dynamic,chunk)
for (i=0; i < n; i++)
c[i] = a[i] + b[i];
} // end of parallel section
}
№34 слайд

Содержание слайда: Директива sections…
Формат директивы sections:
#pragma omp sections [clause ...]
{
#pragma omp section // несколько секций
structured_block
}
Возможные параметры (clause):
private(list),
firstprivate(list),
lastprivate(list),
reduction(operator: list),
nowait
№35 слайд

Содержание слайда: Директива sections
Директива sections – распределение вычислений для раздельных фрагментов кода.
Фрагменты кода:
Выделяются при помощи директивы section.
Каждый фрагмент выполняется однократно.
Разные фрагменты выполняются разными потоками.
Завершение директивы по умолчанию синхронизируется
Директивы section должны использоваться только в статическом контексте.
№36 слайд

Содержание слайда: Пример использования директивы sections…
#include <omp.h>
#define NMAX 1000
void main() {
int i, n;
float a[NMAX], b[NMAX], c[NMAX];
for (i=0; i < NMAX; i++)
a[i] = b[i] = i * 1.0;
n = NMAX;
#pragma omp parallel shared(a,b,c,n) private(i)
{
// продолжение на следующем слайде
№37 слайд

Содержание слайда: Пример использования директивы sections
#pragma omp sections nowait
{
#pragma omp section
for (i=0; i < n/2; i++)
c[i] = a[i] + b[i];
#pragma omp section
for (i=n/2; i < n; i++)
c[i] = a[i] + b[i];
} // end of sections
} // end of parallel section
}
№38 слайд

Содержание слайда: Объединение директив parallel и for/sections
#include <omp.h>
#define CHUNK 100
#define NMAX 1000
void main () {
int i, n, chunk;
float a[NMAX], b[NMAX], c[NMAX];
for (i=0; i < NMAX; i++)
a[i] = b[i] = i * 1.0;
n = NMAX;
chunk = CHUNK;
#pragma omp parallel for shared(a,b,c,n) \
schedule(static,chunk)
for (i=0; i < n; i++)
c[i] = a[i] + b[i];
}
№39 слайд

Содержание слайда: Директивы openmp
№40 слайд

Содержание слайда: Параметр reduction
Параметр reduction определяет список переменных, для которых выполняется операция редукции (объединения).
reduction (operator: list)
Перед выполнением параллельной области для каждого потока создаются копии этих переменных.
Потоки формируют значения в своих локальных переменных.
При завершении параллельной области на всеми локальными значениями выполняются необходимые операции редукции, результаты которых запоминаются в исходных (глобальных) переменных.
№41 слайд

Содержание слайда: Пример использования параметра reduction
#include <omp.h>
void main() { // vector dot product
int i, n, chunk;
float a[100], b[100], result;
n = 100; chunk = 10;
result = 0.0;
for (i=0; i < n; i++) {
a[i] = i * 1.0; b[i] = i * 2.0;
}
#pragma omp parallel for default(shared) \
schedule(static,chunk) reduction(+:result)
for (i=0; i < n; i++)
result = result + (a[i] * b[i]);
printf("Final result= %f\n",result);
}
№42 слайд

Содержание слайда: Правила записи параметра reduction
Возможный формат записи выражения:
x = x op expr
x = expr op x
x binop = expr
x++, ++x, x--, --x
x должна быть скалярной переменной.
expr не должно ссылаться на x.
op (operator) должна быть неперегруженной операцией вида:
+, -, *, /, &, ^, |, &&, ||
binop должна быть неперегруженной операцией вида:
+, -, *, /, &, ^, |
№43 слайд

Содержание слайда: Заключение
Данная лекция посвящена рассмотрению методов параллельного программирования для вычислительных систем с общей памятью с использованием технологии OpenMP.
В лекции проводится обзор технологии OpenMP.
Рассматриваются директивы OpenMP, позволяющие
определять параллельные области,
управлять областью видимости данных,
распределять вычислений между потоками,
выполнять операции редукции.
Дальнейшее изучение технологии OpenMP будет продолжено в одной из следующих лекций.
№44 слайд

Содержание слайда: Литература
Гергель В.П. Высокопроизводительные вычисления для многопроцессорных многоядерных систем. - М.: Изд-во Московского университета, 2010. – 544 с.
Дополнительная литература:
Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. – СПб.: БХВ-Петербург, 2002.
Гергель В.П. Теория и практика параллельных вычислений. - М.: Интернет-Университет, БИНОМ. Лаборатория знаний, 2007.
Гергель В.П. Новые языки и технологии параллельного программирования. - М.: Издательство Московского университета, 2012. – 434 с.
Гергель В.П., Баркалов К.А., Мееров И.Б., Сысоев А.В. и др. Параллельные вычисления. Технологии и численные методы. Учебное пособие в 4 томах. – Нижний Новгород: Изд-во Нижегородского госуниверситета, 2013. – 1394 с.
Скачать все slide презентации Параллельное программирование с использованием OpenMP. Лекция 1 одним архивом:









