Презентация Информационный поиск Лидия Михайловна Пивоварова Системы понимания текста онлайн
На нашем сайте вы можете скачать и просмотреть онлайн доклад-презентацию на тему Информационный поиск Лидия Михайловна Пивоварова Системы понимания текста абсолютно бесплатно. Урок-презентация на эту тему содержит всего 21 слайд. Все материалы созданы в программе PowerPoint и имеют формат ppt или же pptx. Материалы и темы для презентаций взяты из открытых источников и загружены их авторами, за качество и достоверность информации в них администрация сайта не отвечает, все права принадлежат их создателям. Если вы нашли то, что искали, отблагодарите авторов - поделитесь ссылкой в социальных сетях, а наш сайт добавьте в закладки.
Оцените презентацию от 1 до 5 баллов!
- Тип файла:ppt / pptx (powerpoint)
- Всего слайдов:21 слайд
- Для класса:1,2,3,4,5,6,7,8,9,10,11
- Размер файла:330.50 kB
- Просмотров:77
- Скачиваний:0
- Автор:неизвестен
Слайды и текст к этой презентации:
№1 слайд

Содержание слайда: Информационный поиск
Лидия Михайловна Пивоварова
Системы понимания текста
№2 слайд

Содержание слайда: Введение
Информационный поиск – поиск в большой коллекции документов, удовлетворяющих потребности пользователя, сформулированной в виде короткого запроса на естественном языке.
Стремительный рост Интернета и успешное развитие информационно-поисковых систем привели к тому, что современный информационный поиск как дисциплина включает широкий круг вопросов, связанных со сбором, хранением, поиском и представлением самой разнообразной информации; сюда же естественным образом относятся многие задачи автоматической обработки текста.
№3 слайд

Содержание слайда: Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
№4 слайд

Содержание слайда: Индексирование
Поиск по большим коллекциям не может осуществляться в режиме реального времени.
Для быстрого поиска коллекция предварительно обрабатывается и по ней строится индекс(ы) – набор атрибутов, которые упорядочены в удобном для поиска порядке.
В случае полнотекстового поиска такими атрибутами являются слова (словосочетания), приведенные к нормальной форме.
№5 слайд

Содержание слайда: Структура индекса
№6 слайд

Содержание слайда: Процесс индексирования
Анализ структуры – выделение заголовков, абзацев и т.п.; удаление html-разметки и т.д;
Токенизация – разбиение текста на слова, удаление знаков препинания;
Удаление стоп-слов - высокочастотных служебных слов (предлогов, союзов и т.п.);
Лемматизация – приведение слов к нормальной (например, словарной) форме;
Взвешивание
№7 слайд

Содержание слайда: Взвешивание
В индексе хочется учитывать не только сам факт вхождения слова в документ, но и «вес», т.е. информацию о частоте данного слова в документе.
Однако саму по себе частоту использовать плохо, поскольку слова распределены в языке неравномерно: некоторые встречаются гораздо чаще других
№8 слайд
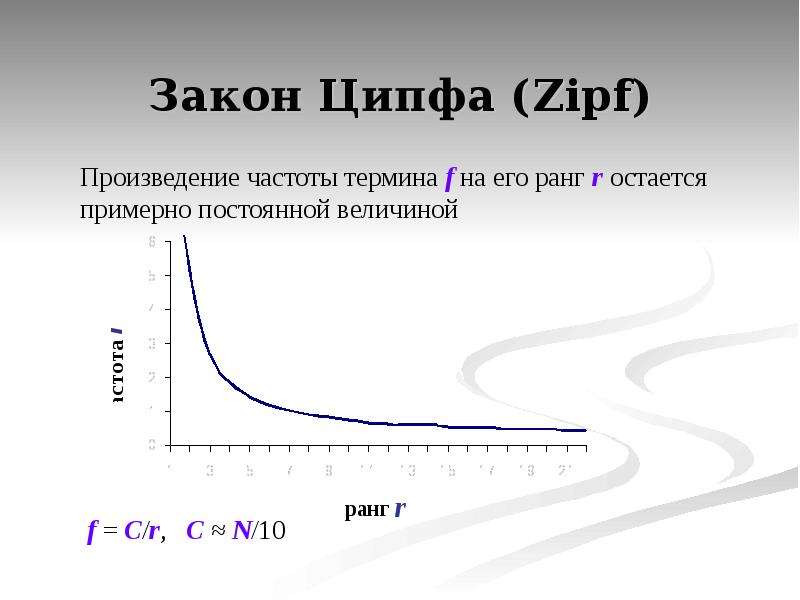
Содержание слайда: Закон Ципфа (Zipf)
№9 слайд
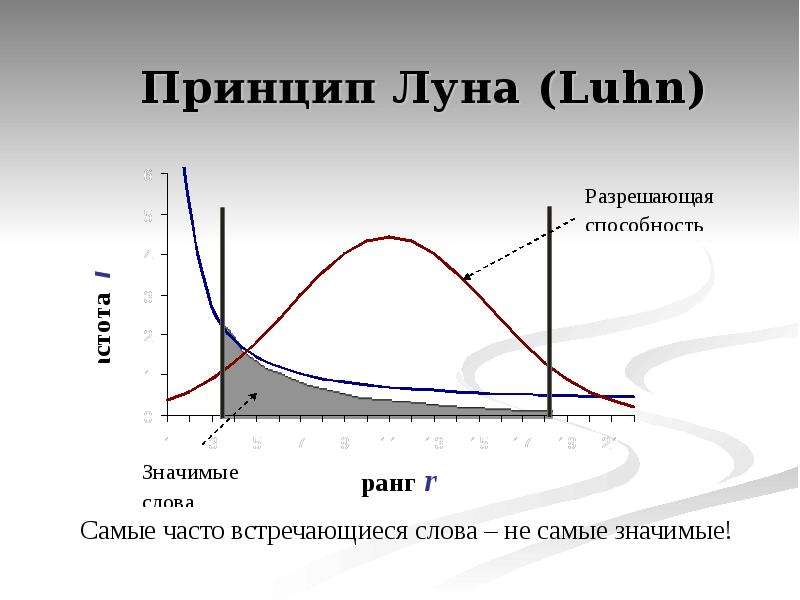
Содержание слайда: Принцип Луна (Luhn)
№10 слайд

Содержание слайда: Классический метод взвешивания: tf-idf
tf – относительная частота слова в документе
idf – обратная документальная частота (чем меньше в коллекции документов, в которые входит это слово, тем idf больше)
№11 слайд

Содержание слайда: Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
№12 слайд
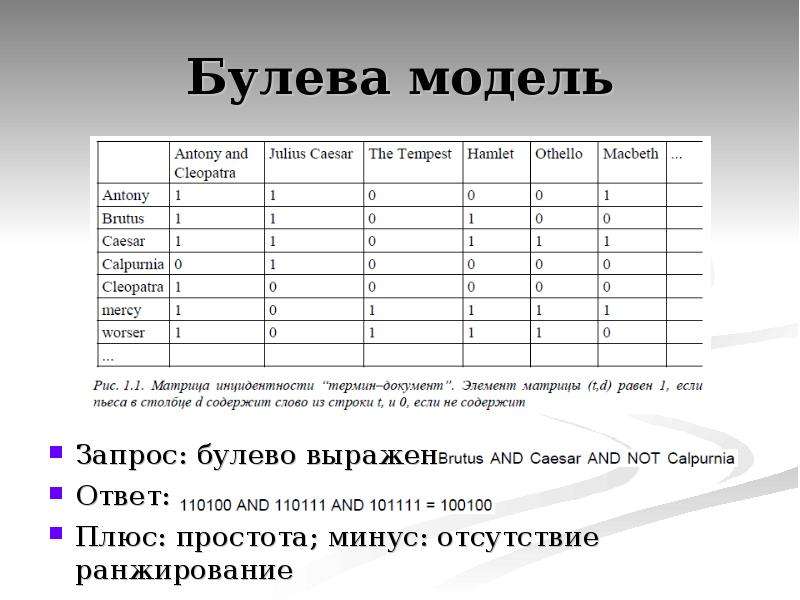
Содержание слайда: Булева модель
Запрос: булево выражение:
Ответ:
Плюс: простота; минус: отсутствие ранжирование
№13 слайд

Содержание слайда: Векторная модель
Коллекция из n документов и m различных терминов представляется в виде матрицы mxn, где каждый документ – вектор в m-мерном пространстве.
Веса терминов можно считать по разному: частота, бинарная частота (входит – не входит), tf*idf…
Порядок слов не учитывается (bag of words)
Матрица очень большая (большое число различных терминов в гетерогенной коллекции).
В матрице много нулей
№14 слайд
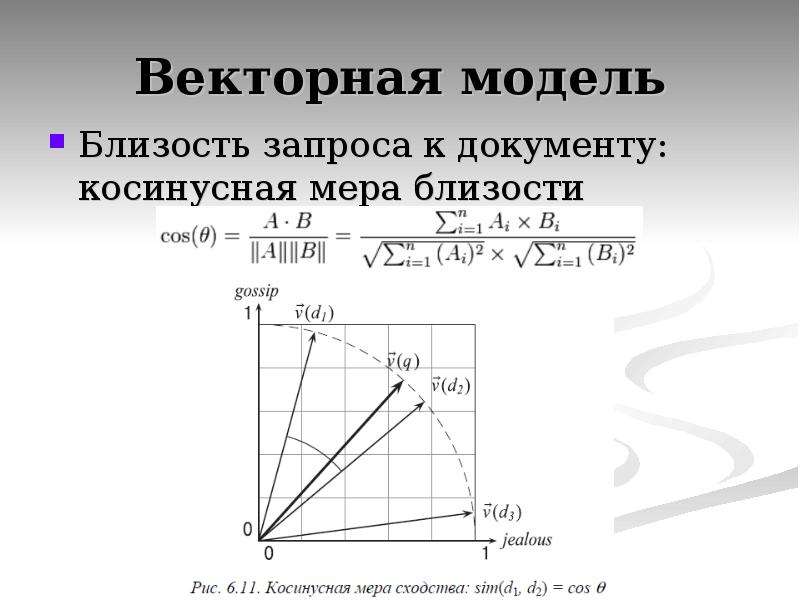
Содержание слайда: Векторная модель
Близость запроса к документу: косинусная мера близости
№15 слайд

Содержание слайда: Вероятностные модели
Вероятность вычисляется на основе теоремы Байеса:
P(R) – вероятность того, что случайно выбранный из коллекции документ D является релевантным
P(d|R) – вероятность случайного выбора документа d из множества релевантных документов
P(d) – вероятность случайного выбора документа d из коллекции D
№16 слайд

Содержание слайда: Вероятностные модели
Решающее правило заключается в максимизации следующей функции:
№17 слайд

Содержание слайда: Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
№18 слайд

Содержание слайда: Оценка информационного поиска
Полнота (recall):
R = tp / (tp+fn)
Точность (presicion):
P = tp / (tp+fp)
F-мера:
Аккуратность (accuracy):
A = (tp + tn) / (tp + tn +fp +fn)
№19 слайд

Содержание слайда: Содержание
Индексирование
Модели информационного поиска
Оценка информационного поиска
Роль автоматической обработки текста в информационном поиске
№20 слайд

Содержание слайда: Уровни анализа языка
Морфологический анализ
– признан необходимым для информационного поиска, особенно для флективных языков (например, русского); сюда же относится предсказательная морфология (для незнакомых слов), а также исправление опечаток.
Синтаксический анализ
– уже из самого понятия “bag of words” следует, что синтаксис здесь практически не используется; исключения: линейный порядок слов, именные группы, сборка терминологических словосочетаний.
Семантический анализ
– в классическом информационном поиске как правило не используется; некоторые элементы лексической семантики применяются при расширении запросов, индексировании документов и составлении каталогов.
№21 слайд

Содержание слайда: Источники
J. Savoy, E. Gaussier Information Retrieval // Handbook of natural language processing, Second Edition Editor(s): Nitin Indurkhya; Fred J. Damerau, Goshen, Connecticut, USA – 2010 – pp. 455-484
К. Д. Маннинг, П. Рагхаван, Х. Шютце Введение в информационный поиск – Вильямс, 2011
А.В. Сычев Информационно-поисковые системы - http://company.yandex.ru/academic/class2006/sychev.xml
Скачать все slide презентации Информационный поиск Лидия Михайловна Пивоварова Системы понимания текста одним архивом:









